
Introduction
“Sometimes” just having all the database backups in one place is not enough. In fact, most of the time, putting all the eggs in one basket is a bad idea. You want to have some piece of mind that during the time of crisis, your all the database backups is restorable. This is probably why, many companies offered offsite backup services back in the day before the public cloud became the thing. While public cloud changed a lot if things, the need for offsite is still there. This blog is going to discuss how to send a copy of your SQL Server database backup files from AWS EC2 to an AWS S3 bucket.
Problem
Nowadays, with all the provisioning happening in the cloud and all the data stored on a highly reliable provisioned AWS EBS disks, this seems like less of an issue. At same time, what would happen if an entire zone went down? While this is rarely happens, you better have an insurance policy, such as a sync/store for your backups in a different zone, to make it more reliable. Which brings us to having a copy of backups on your AWS S3 bucket.
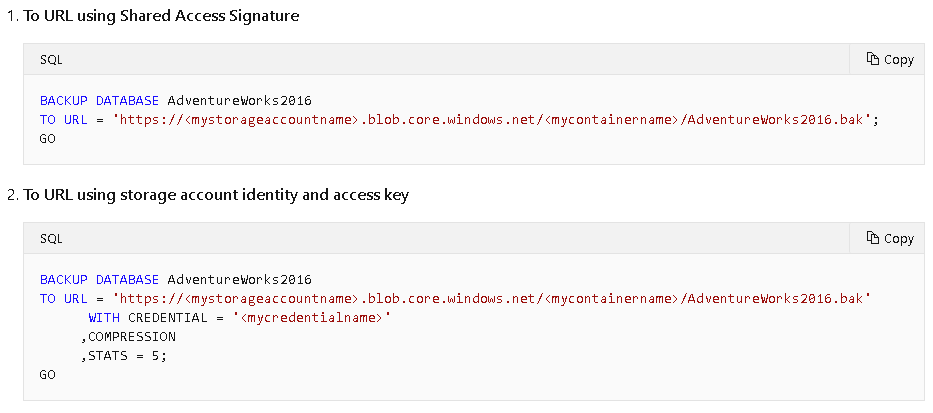
While Microsoft Azure offers a backup to URL option native to the SQL Server (see Fig #1), AWS customers do not have that luxury. Backing up or syncing files to the popular S3 bucket is a bit more involved. Luckily, it’s actually not that hard using AWS Command Line Interface (“CLI”). We can backup databases to an attached EBS volume and then copy those files to an S3.
Solution
The following steps will guide you on how to accomplish just that – copy/synchronize your database backup files to an S3 bucket.
- Install the AWS CLI for Windows from here – https://awscli.amazonaws.com/AWSCLIV2.msi
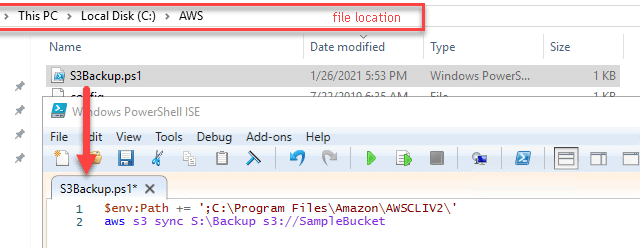
- Create a new S3 bucket (if necessary) that will store your backup files. We will use a PowerShell file to copy the backups. The PowerShell file is going to call AWS S3 sync command that will start the file synchronization process between local S:\Backup folder and S3://SampleBucket (see Fig #2)
What is AWS CLI S3 Sync command?
The s3 sync command synchronizes the contents of a bucket and a directory, or the contents of two buckets. Typically, s3 sync copies missing or outdated files or objects between the source and target. However, you can also supply the --delete option to remove files or objects from the target that are not present in the source
Syntax: $ aws s3 sync <source> <target> [--options]
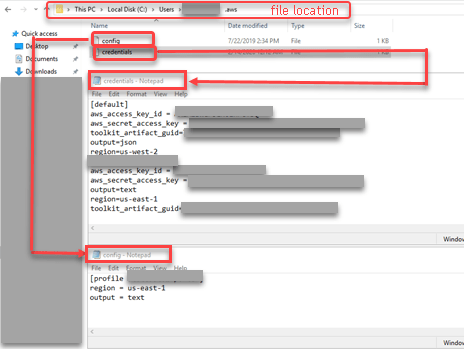
- Add both config and credentials files to an .aws folder that is under the user folder (see Fig #3). While Config file contains just pieces of the profile data, Credentials file contains all the keys to the “S3 kingdom”
- Create an extra SQL Server step (last step) to all the backup jobs to run the PowerShell file (see Fig #4)

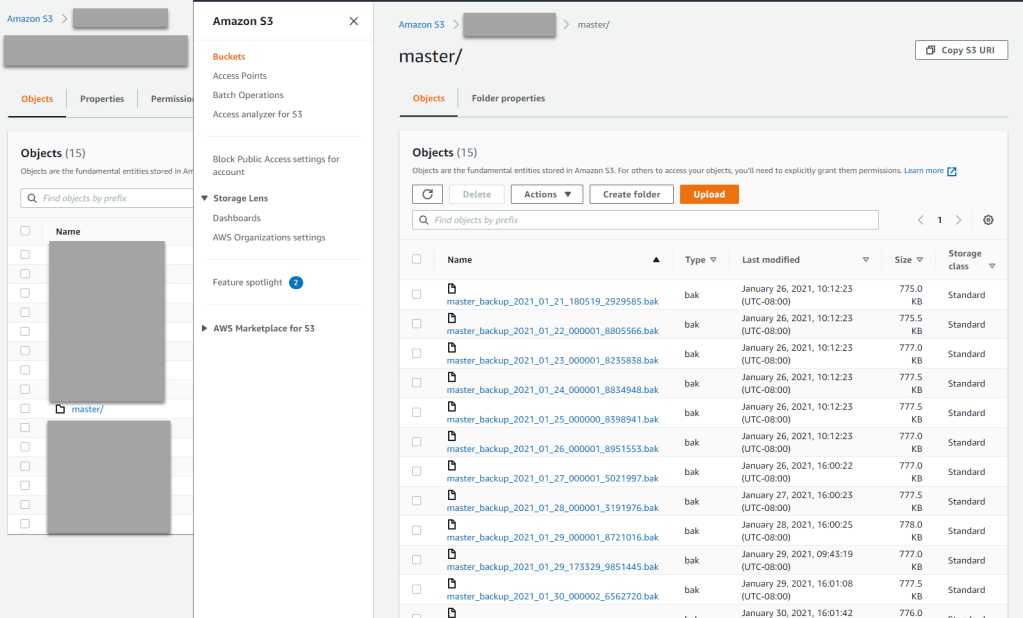
- Confirm that the job is running successfully and you see the same database backup files on on your attached EBS volume exist on S3 bucket (see Fig #5)
Relax and have your favorite cold or hot beverage. Your Cloud DBA world is a bit safer now – you have implemented an offsite backup process. If your AWS EC2 instance would become unavailable for any reason or maybe your servers are compromised and all the database files are encrypted, you can safely restore from S3 bucket.
Disclaimer
This blog post is partially based on the following resources:
